去年还在说"AI Agent 是未来",今年 Gartner 的数据出来了:多智能体系统相关咨询量在 18 个月内激增 1,445%。不是倍增,是十四倍。
但与此同时,有一个让我反复思考的矛盾:越来越多的团队喊着"我们在做 Agent",但产品要么慢得像乌龟,要么成本高到跑不起来,要么——根本就没比一个好的 Prompt 强多少。
问题几乎都出在同一个地方:对 Agent 架构的理解,停留在"调用 LLM + 接几个工具"的层面。这距离一个真正能跑的 Agent 系统,差得远。
一、为什么"现在"是搞懂 Agent 架构的最佳时机
有一个认知误区根深蒂固:很多人把 AI Agent 理解成"更聪明的聊天机器人"——给它一个问题,它多想几步,调一下工具,返回答案。这个理解在 2023 年勉强够用。但到了 2025-2026 年,这个定义已经失效了。原因有三:
第一,任务复杂度跃升。真实的生产需求——比如"帮我整理 30 份合同里的违约条款并生成摘要报告"——无法被单次 LLM 调用解决。它需要分解、并行执行、结果聚合,还要能在中途出错时重试。这是架构问题,不是提示词问题。
第二,框架已经收敛。LangGraph、AutoGen、CrewAI 三个框架的出现,意味着社区已经在"如何构建 Agent 系统"这个问题上跑出了方法论共识。选错框架不只是技术负债,而是方向性错误。
第三,成本结构改变了一切。Anthropic 工程博客披露,多智能体系统消耗的 Token 约是普通对话的 15 倍。在精准选型和盲目堆 Agent 之间,成本可能相差一个数量级。
二、先建立一个正确的认知地基
AI Agent 最精炼的定义:
注意关键词:持续迭代。这是 Agent 和普通 LLM 应用的本质区别。普通应用是一问一答;Agent 是一个运行中的循环,每一步的输出是下一步的输入。
把 Agent 想象成一个新入职的聪明助理。你告诉他"帮我约一个下周三的客户会议",他不会只回答"好的"——他会先查你的日历,发现下午有冲突,主动建议改到上午,发邀请邮件,等对方回复,没回复再催一次。每一步都依赖上一步的结果。这就是循环,这就是 Agent 的本质。
三、Agent 的"中枢神经系统":四大核心组件
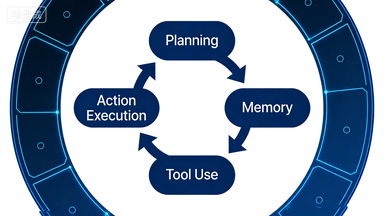
图1:AI Agent 四大核心组件构成闭环反馈回路(豆包 AI 生成)
一个 AI Agent 系统底层由四个紧密耦合的模块支撑,它们构成一个反馈回路:推理结果驱动规划,规划调度工具,工具执行结果写入记忆,记忆反哺下一轮推理。
Planning:任务怎么切开执行
规划模块的核心职责是将模糊的高层目标转化为可执行的原子化子任务序列。目前生产环境里效果最好的是层次化规划:先生成高层计划(3-5 个大步骤),执行时再即时生成细粒度子任务。这和人类处理复杂项目的方式高度吻合——先立项,再排期,不要一开始就把所有 TODO 列完。
Memory:最被低估的模块
Memory 的设计质量,直接决定 Agent 能做多长的任务。
| 类型 | 载体 | 容量 | 持久性 | 访问速度 |
|---|---|---|---|---|
| 短期记忆 | LLM Context Window | 有限(受模型限制) | 会话内 | 极快 |
| 长期记忆 | 外部向量数据库 / KV 存储 | 理论无限 | 跨会话 | 需检索延迟 |
真正的工程挑战在于信息如何在两层之间流动。有三个常见的反面教材:
- 传得太少:工作者 Agent 频繁找编排者要上下文,产生大量无效通信轮次
- 传得太多:把所有历史记录塞进 Context,Token 爆炸,推理质量反而下降
- 过滤策略差:把不重要的中间结果保留,把关键的用户约束丢失
Tool Use:Agent 真正的"手"
工具调用有两个容易踩的坑:
Action Execution:闭环的最后一公里
设计原则:最小权限 + 幂等性。最小权限好理解——Agent 能读文件就别给写权限。幂等性更关键:同一个动作执行一次和执行两次,结果应该相同。否则网络超时重试会产生重复订单、重复邮件这类灾难性后果。
四、推理的灵魂:ReAct 框架拆解
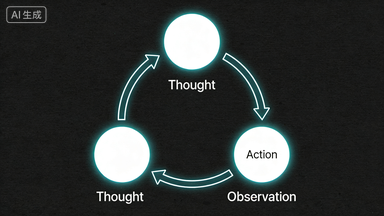
图2:ReAct 框架中 Thought-Action-Observation 的循环推理过程(豆包 AI 生成)
四大组件是骨架,但 Agent 怎么"思考",由推理框架决定。目前事实标准是 ReAct(Reasoning + Acting),2023 年由 Google Research 提出(arXiv:2210.03629)。
它的核心思想用一句话概括:
这听起来简单,但效果显著。它将 Agent 的行动空间从"工具调用空间"扩展为"推理空间 + 工具调用空间",让每一步决策都有可追溯的逻辑链。一个典型的 ReAct 循环:
关键点:Observation 会反馈回 Thought,形成新一轮推理。当 Observation 不符合预期,Agent 会重新规划而不是盲目继续——这是 Agent 能"自我纠错"的根本原因。
| 推理范式 | 机制 | 适用场景 | 局限性 |
|---|---|---|---|
| CoT(思维链) | 纯推理链,无工具调用 | 数学、逻辑推理 | 无法获取外部信息 |
| ReAct | 推理 + 行动 + 观察循环 | 需要外部工具的任务 | 循环过深时 Token 成本高 |
| Plan-and-Execute | 先全局规划,再逐步执行 | 长流程编排任务 | 规划阶段无法适应执行中变化 |
| 树搜索 | 多分支并行探索 | 复杂决策树、博弈类任务 | 计算成本极高 |
五、多智能体的真实代价
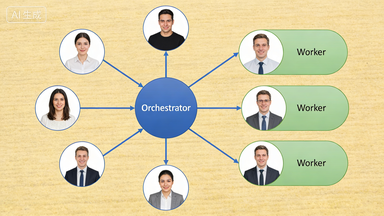
图3:编排者负责分解与调度,工作者专注各自领域——职责边界清晰是这个模式的核心优势(豆包 AI 生成)
单体 Agent 够用时,不要引入多智能体。这是我最想传递的工程判断。
先说一个让很多人意外的数据:Google Research 2025 年的研究发现,多智能体系统的性能收益与任务的并行性高度相关:
为什么序列任务反而下降?因为 Agent 之间的通信把推理过程碎片化了,引入了大量噪音。多智能体不是银弹,它只在特定任务结构下才能发挥优势。
Orchestrator-Worker:生产环境最实用的编排模式
当你真的需要多智能体时,编排者-工作者模式是目前生产部署最广泛的选择。
六、框架选型:LangGraph vs AutoGen vs CrewAI
三个框架代表三种不同的架构哲学,没有绝对的优劣,只有是否匹配你的任务结构:
| 维度 | LangGraph | AutoGen | CrewAI |
|---|---|---|---|
| 核心抽象 | 有向状态图 | Agent 对话 | 角色 + 流程 |
| 状态管理 | 显式,强大 | 隐式,灵活 | 中等 |
| 工作流控制 | 精细(条件分支/循环) | 松散(对话驱动) | 中等(流程定义) |
| 学习曲线 | 陡峭 | 中等 | 平缓 |
| 适合场景 | 复杂非线性工作流 | 研究/协作问题求解 | 角色清晰的生产任务 |
| 生产就绪度 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| 快速原型 | 较慢 | 中等 | ⭐⭐⭐⭐⭐ |
七、现实层面的挑战:没人告诉你的那些事
真实的 Agent 工程,有几个挑战比论文里写的难得多:
延迟累积。生产级应用面向用户的延迟目标通常 <2.1 秒。单体 Agent 一轮推理可能消耗 1-2 秒,ReAct 循环跑 3 轮就逼近上限。多智能体再加通信开销,30% 以上的延迟增幅是真实代价。
不可预测的失败模式。LLM 的非确定性会传播到整个 Agent 系统。测试环境正常运行的工作流,在生产中遇到特殊输入时可能进入死循环。这要求设计阶段就内置最大步骤限制和强制中断机制。
可观测性几乎是零起点。传统监控对 Agent 无效——Agent 的"错误"往往不是异常抛出,而是给出了一个看起来合理但业务上错误的答案。LangSmith、Arize 等 LLM Observability 工具正因此崛起,但整个领域仍处于早期。
八、作者观点:一个可以带走的选型框架
最后一点值得反复强调:Agent 架构的核心竞争力不是 Agent 数量,而是上下文管理的精准度。谁能把"传多少信息给哪个模块"这件事做好,谁的系统就能在成本可控的前提下跑得又快又准。
2026 年的 Agent 工程,已经从"能不能运行"进化到了"能不能持续、低成本、可观测地运行"。这个转变,就发生在架构层。